AI timeline modes should be significantly before medians

I think your proabability distributions over possible AI timelines should have its mode significantly before its median. Here are a few different (highly related!) reasons for this:
Semi-informative priors
The most naive prior you could have about AGI arrival dates is maybe something like a laplace prior. This has the mode now, significantly before the median. (For more on semi-informative priors, see here.)
We live in a special time
AI is currently improving a lot per year. Specifically, there’s recently been a large scale-up in compute, with accompanying impressive new model-performance. Right now, two things are happening:
Models are being scaled up even further, by spending more.1
Increasing spending by an order of magnitude gets 10x more expensive each time you do it, so we should expect the trend towards increased spending to slow off significantly within the next few orders of magnitudes. This is important if your timelines is largely based on amounts of training compute.
Algorithms are being adapted to these new big model-sizes. (E.g. scaling laws, see chinchilla, or figuring out how to best do step-by-step reasoning, see minerva.)
In general, I expect to see significant performance boosts in the years after scaling up training compute — not just immediately when training compute is scaled up.
By contrast, we have no idea whether any particular future years will be such a special time.
I do trust a sense that AGI isn’t right around the corner, e.g. just a few months away. But I think this knowledge decays over the course of a few years, and that 5-10 years away from now both has some benefits from being close to the special now and that we can’t confidently rule it out.
You might want to reserve some probability mass for non-specific lateness
I sometimes see AI timelines include non-trivial probability mass on things like “maybe we’ll never build AGI”, “maybe I’m just confused and shouldn’t trust my inside view”, or “maybe we need a fundamentally new unpredictable paradigm”. These will typically push your median later (by taking up probability mass at the end) but mostly shouldn’t shift the mode.
There’s a lot more years in the long-term than in the near-term
Let’s say that your median AI timeline is X years out. Between now and then, there’s just X years. But my sense is that it’d be quite unjustified to have a precipitous drop-off in probability within the X years after the median, and that the drop-off should instead be quite gradual. But this means that, if we look at all years with non-trivial probabilities of AGI, more of them will come after the median than before the median, implying that the years before the median must on average have higher probabilities.
(Relatedly, after looking at some graphs of AI timelines, I’ve come to appreciate “there’s a lot more years in the medium future than in the near future” as a pretty decent argument against very short timelines.)
Implications
So why does this matter? Sometimes people describe their AI timelines by quoting a median, and it’s easy to get the impression that those median timelines are what we should be planning for. I think this might be a mistake. Consider this graph, of a timeline with a median of ~2040 but a mode of ~2030.
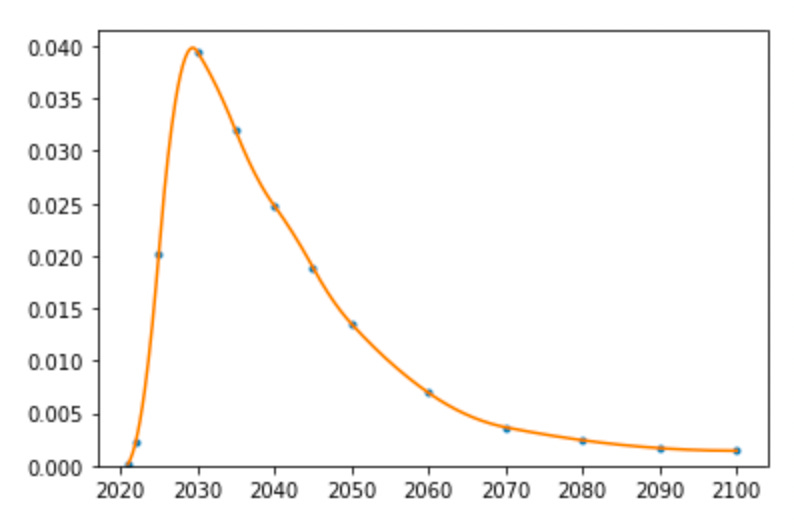
When I look at this, it intuitively doesn’t at all seem clear to me that we should be aiming to have positive impact if AGI happens in 2040, as opposed to 2030.
In particular, sometimes people cite leverage arguments as reasons to focus on short timelines. And sometimes people criticize leverage arguments as not working well in practice, because people will do much better work if they work with beliefs that they actually understand and have models for than if they imagine themselves into some improbable situation where they have very high leverage. Looking at a graph like the above makes me notice that in practice, people who have median-2040 timelines will often place more probability mass on “AGI in 2030” than “AGI in 2040”, and so it’s totally unclear to me whether criticisms like that should push them towards the former or the latter. My best guess is that it doesn’t matter much, and so that it makes sense to think about leverage arguments when choosing between them.
Though I’m a bit surprised that spending hasn’t increased more since GPT-3.