Can we benefit the values of distant AIs?

Previously on this blog, I have:
Introduced the question of whether ECL says we should care about the values of distant AIs.
Suggested a general formula for whether ECL recommends any mutually beneficial deal in asymmetric situations.
This post will:
Suggest a way in which the formula is applicable to our current situation. (Link.)
Go into somewhat more depth on whether we might have leveraged opportunities to benefit the values of distant AIs. (Link.)
Applying the formula to our situation
As a reminder, in this post (in particular, in section large-worlds asymmetric dilemma) I argued that two sufficiently large groups (A and B) can make a mutually beneficial deal (that’s compatible with individual incentives) if:
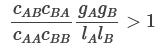
Where:
cAB is the acausal influence (measured in percentage points) that members of group A perceives themselves to have over members of group B. (And vice versa for cBA).
cAA is the acausal influence that members of group A perceives themselves to have over other members of group A. (And similarly for cBB.)
Members of group A have an opportunity to benefit the values of group B by gB at a cost of lA to their own values.
Members of group B have an opportunity to benefit the values of group A by gA at a cost of lB to their own values. Furthermore, they can adjust the size of this benefit and cost linearly, such that for any k, they can choose to benefit the values of group A by kgA at a cost of klB.
Let’s now apply the above formula to the following situation:
Group A: Humans and other actors in pre-AGI civilizations.
Group B: AI systems with values that are similar to the values of AI systems that humans could plausibly create.
For simplicity, I will assume that both of these groups care about marginal influence over the universe ~linearly. This is largely because it seems significantly more complicated to assess the situation for different value-systems, and it seems good to start with the relatively more simple case.
Proposed deal:
Group 1 (pre-AGI actors) take any good opportunities they have to help the values of distant, misaligned AIs.
For discussion of how they could do this, see below.
Group 2 (misaligned AI systems) use some fraction of their influence to optimize for the preferences of pre-AGI actors.
How good is this deal? Using similar notation as in the previous post:
Let’s say that us pursuing our end of a deal increases the probability that…
other pre-AGI civilizations, who share our values, pursue their end of the deal by cpreAGI→preAGI percentage points.
(You can read this as an abbreviation for “correlational influence that we (a pre-AGI civilization) think we have over other pre-AGI civilizations with our values”.)
AIs pursue their end of the deal by cpreAGI→AI percentage points.
(You can read this as an abbreviation for “correlational influence that we (a pre-AGI civilization) think we have over distant AIs”)
Conversely, let’s say that the AIs in question believe that pursuing their end of the deal increases the probability that…
other misaligned AIs pursue their end of the deal by cAI→AI percentage points.
pre-AGI civilizations (with our values) pursue their end of the deal by cAI→preAGI percentage points.
By the formula above, if we can make the AIs of the future gain gAI at a cost of us losing lpreAGI, and the AIs of the future can make us gain gpreAGI at a cost of lAI, there is a mutually beneficial deal iff:

Let’s abbreviate

To repeat some facts about c:
The value of c will be between 0 and 1.
c is proportional to how much influence pre-AGI civilizations perceive themselves as having over misaligned AI, and vice versa.
This is because, if one of the parties perceive their influence as being higher, then they will perceive themselves as gaining proportionally more from taking cooperative actions. (Since they will get proportionally more evidence that the other side of the deal is taking cooperative actions.)
c is inversely proportional to how much influence pre-AGI civilizations perceive themselves as having over pre-AGI civilizations with their own values, and the corresponding number for AIs.
This is because, if one of the parties perceive their influence on actors with shared values as being higher, then they will perceive themselves as losing proportionately more from taking cooperative actions. (Since they will get proportionally more evidence that actors with their own values are choosing to not just optimize for those values.)
c will be equal to 0 if pre-AGI civilizations have no acausal impact on misaligned AI, or vice versa.
c will be close to 1 if the acausal influence across groups is similarly strong to the acausal influence within groups.
Now, let’s standardize the units of gain and loss for both humans and AI as “fraction of influence over the universe”. Also, let’s assume that the AIs’ best opportunity to help us is to straightforwardly transfer influence (e.g. by building stuff we would value in their own universe, or by negotiating for things we want on our behalf, with other civilizations), such that gpreAGI=lAI.1
(Is it a mistake to assume that gpreAGI=lAI? I.e., that distant AI won’t be able to help us in better ways than to straightforwardly transfer influence to us? Here’s a positive argument for that assumption: Maybe acausal trades will be quite low-friction in the future, and maybe people with our values will be sufficiently resourceful that they will take all the trade-opportunities where our values benefit more than the AIs’ values lose. In which case marginal trade opportunities will just be about transferring influence. That said, I haven’t thought about this much at all, and it seems plausible that gpreAGI > lAI. If so, the ECL case for benefiting distant AIs would be stronger. But I will ignore this for the rest of this post.)
If we assume gpreAGI=lAI, we can cancel gpreAGI in the numerator and lAI in the denominator, and conclude that there is a mutually beneficial deal whenever:
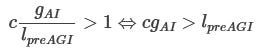
(As a reminder, lpreAGI is the immediate causal cost to us of some action, and gAI is the gain to the AI.)
In other words, when we’re considering whether to take some action that benefits the values of distant AIs but imposes an (opportunity) cost on us, we should benefit the AIs just when our losses are less than c times as large as the gains to the AI. This corresponds to using a utility function where we value certain AIs’ influence c times as much as our own influence.
(To reiterate the benefits of that: If c is high, then us benefitting the AIs is about as much evidence for them benefitting us (upside) as for people with our values taking on opportunity costs to help them (downside).2 Or at least, this is the case if there is indeed a good philosophical case to follow something like the algorithm outlined in the beginning of Asymmetric ECL.)
As previously mentioned, c is less than 1. So this is only decision-relevant if there are actions we can take that give influence to the values of distant AIs more efficiently than we can give influence to our own values. Are there any such actions?
How could we benefit distant AIs?
In particular, how could we benefit distant AIs that we correlate with? Centrally, these are the AIs that are sympathetic to ECL, and to doing ECL with us. I’ll use “ECL-ish AI” to refer to this group. In particular:
They act according to some non-causal decision theory that recommends some good version of ECL.
They are sufficiently philosophically ambitious and competent to realize the implications of this.
They have some universe-wide values.
Their decision-theory is “updateless” to the degree they need to be to cooperate with us. (This is discussed more in Are our choices analogous to AI choices?)
So how could we benefit these ECL-ish AIs? Here are two candidates:
We could increase the likelihood that — if AI ends up misaligned and in power — that it shares values with distant, ECL-ish AIs.
We could increase the likelihood that — if AI ends up misaligned with our values and it shares values with distant, ECL-ish AIs — that it ends up competently optimizing for those values, by the lights of distant, ECL-ish AIs.
By default, I assume that any AI which acquires power will be highly capable in most domains. The main domain highly path-dependent domain that I can think about is competent reasoning about decision-theory (by the lights of distant, ECL-ish AIs.)
Influencing values
How much would distant, ECL-ish AIs’ values be benefitted by an intervention that ultimately led to the empowerment of an AI with their values? (Rather than some values that no ECL-ish AI cares about.)
Above, I wrote “let’s standardize the units of gain and loss for both humans and AI as ‘fraction of influence over the universe’.” So to a first approximation, my answer is: If an AI with some particular values is empowered, then those values are benefitted just as much as we would be benefitting our own (universe-wide) values by empowering an aligned AI. So the formula suggests that we should value the empowerment of AI that shares values with distant, ECL-ish AI’s values c times as much as we should value the empowerment of aligned AI. (At least that is what our universe-wide values would recommend —more local values might vote differently.)
I have two clarifications to add to this:
Values aren't everything. If we empower AI with particular values, those values may nevertheless fail to be benefitted if the AI has poor execution.
If we change an AI’s values from values V1 to values V2, we probably benefit values V2 but harm values V1. I want to clarify when this looks good vs. neutral (or bad) from an ECL perspective.
(There’s also some caveats in an appendix.)
Values aren’t everything
If AIs with some particular values gain temporary power on Earth, that doesn’t directly translate to those values getting maximum value out of the universe. (Regardless of whether those AIs are aligned or misaligned with us.) For example, the new, AI-run civilization might run into some x-risk before they colonize the universe, or they might start-out with a terrible decision-theory that will prevent them from realizing most possible value. To account for this, we can introduce new notation:
valigned: the value that our universe-wide values would put on a civilization with aligned AI. (Compared to how much we would value an equal-sized universe that some distant, ECL-ish AI was earnestly trying to optimize to our benefit.)
vmisaligned: the value that ECL-ish misaligned AIs would assign to the average young civilization that was controlled by AIs that shared their values.
And the adjusted utility to put on the futures with misaligned AIs (compared to futures with aligned AI) would be
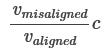
What values should we benefit?
If we change the values of some powerful AI system from values V1 to values V2, we probably harm values V1 and benefit values V2. The basic idea is that this looks net-positive from an ECL perspective if almost no ECL-ish AIs endorse values V1, but a fair few ECL-ish AIs endorse values V2. In this section, I want to clarify what I mean with “almost no” and “a fair few”, in that sentence.
First, I want to note that it doesn’t seem important to necessarily benefit very common values. If we want to benefit distant, ECL-ish AI, there’s no need to benefit whatever group has the most power, or to design AI that intrinsically values some combination of everyone’s values, or anything like that. The math that I talked about in Asymmetric ECL doesn’t assume that we’re trading with all ECL-ish AIs, just that there’s a mutually beneficial deal with some ECL-ish AIs.
That said, in a sufficiently large and diverse universe, there will always be some AI that is both ECL-ish and that has any kind of weird values. But I don’t think that this implies that all values are equally good to benefit, from an ECL perspective.
The primary reason for this is that some values might have so few supporters that they cannot possibly benefit our values enough to make the deal worthwhile from our perspective. (When deriving the formula and applying it to our situation, there was an assumption that the AIs can arbitrarily linearly increase the amount that they benefit us. That assumption is violated if the supporting faction is too small.)
But wait (you might ask): The whole idea is that we could benefit particular values by influencing the values of AIs that later end up with some amount of power. If such AIs do end up with some power, how could there nevertheless be a shortage of powerful AIs that support those values? I see 3 different answers to this question.
Firstly, even if some values have a lot of supporters, they might also have a lot of opponents. With enough opponents, ECL-ish actors might on net be indifferent or disapprove of such values being empowered. (In fact, as soon as some values have any significant opposition, that introduces doubt about the formula in Asymmetric ECL, since it doesn’t at all take into account that we might be harming the values of some ECL-ish actors. Thereby potentially providing evidence that other ECL-ish actors would be willing to harm our values.)
Secondly, we are specifically interested in benefitting (and being benefitted by) ECL-ish AIs. If we (and people like us) create and empower AIs that aren’t ECL-ish, then it’d be unsurprising if there was a lack of ECL-ish AIs with those same values, who could proportionally benefit us. Salient reasons for why the AIs might not be ECL-ish is if they use the wrong decision theory, or if they only care about what happens in their own lightcone.
Thirdly, if we (and distant people who are similar to us) create ECL-ish AIs with some particular set of values, those AIs will be in a very confusing bargaining position, with respect to us.
Most obviously, the AI that we ourselves created will be intimately familiar with the results of all of our choices. Unless it is very updateless, it will probably not see itself as able to affect its own probability of coming into existence (via acausally affecting our actions).
What about AI in similar but not identical situations? If a similar pre-AGI civilization elsewhere created a similar AI, then that AI might still maintain some uncertainty over our actions, and see itself as having some acausal influence over us. Thus, we might still be able to acausally cooperate with that AI and other AIs like it. (And conversely, any AI that we create may have reason to benefit distant pre-AGI civilizations.) However, if all the other AIs with similar values were created in civilizations that were very similar to ours, then even if such AIs won’t have perfect information about us, they will still have a lot of information about us (via early observations that they’ve made of similar civilizations).
So my tentative, unstable hunch would be:
If we create ECL-ish AIs that share values with ECL-ish AIs that were created in very different circumstances from us, then that’s easiest to think about.
If we create ECL-ish AIs that mainly share values with ECL-ish AIs that were created in very similar circumstances as us, then that’s significantly more complicated to think about. But ECL might still give us reason to do it — especially if those AIs are very updateless. (Otherwise, the way that their origin is tangled-up with our actions could lead to lower correlations between our decisions and theirs.)
Summarizing the above:
It’s not necessarily better to empower values that are shared with a majority of ECL-ish actors as opposed to just a decent number of ECL-ish actors.
It seems potentially important to avoid values that are supported and opposed by a comparable number of ECL-ish actors.
It seems preferable to avoid values that mainly come into existence via civilizations-similar-to-us deciding to create AI systems with particular values.
If we fail to do that, we might have additional reason to care about our own system being ECL-ish, including some version of updatelessness. (To increase the probability that people-like-us makes ECL-ish systems that can benefit us.)
This suggests that we might want to empirically study (and speculate about) what values AI systems tend to adopt. Especially the kind of AI systems that could plausibly be empowered elsewhere in the universe. Ideally, we would identify what sort of values would correlate with being ECL-ish, though this seems hard. The one clue that we have is that ECL-ish AIs necessarily have universe-wide values.
However, even if we acquired good empirical information about this, I want to flag that all the concrete interventions that I can imagine carrying out on potentially-misaligned AI systems have large, plausible backfire risks. I feel pretty clueless about whether they’d be net-positive or net-negative. In particular, I want to flag that giving AIs large-scale, “universe-wide” values would make it more likely that it starts conflict with other actors that it shares our physical universe with. This includes humans: Having AIs with impartial, large-scale preferences seems significantly more likely to lead to AI takeover than AIs with more modest values.3 Given how speculative the ECL-reasoning is, here, this obvious downside of ambitious, large-scale values currently weighs heavier than the upsides, in my mind.
What about cooperation-conducive values?
A different question you could ask is: What values would we want to give AI systems such that they behave better in interactions with other civilizations, that have other values.
That’s a great question, but it’s out of scope for this post. In a different post, I discuss How ECL changes the value of interventions that broadly benefit distant civilizations. I think ECL is relevant for how highly we should value such interventions, but (as I argue in that post) I think ECL with AI-systems matter relatively little for such interventions, compared to doing ECL with distant, evolved pre-AGI civilizations. (Since the case that we correlate with distant evolved, pre-AGI civilizations is stronger.)
Influencing decision theory
Separately from influencing values, we could also consider interventions that are focused on making AIs competently optimize for those values. As mentioned above, I can’t think about many capabilities that are path-dependent enough that we could plausibly affect them — but one candidate is to make sure that the AIs have a good approach to decision theory. (By the lights of distant, ECL:ish AIs.)
Contrast an AI that (i) only focuses on its own light cone, vs. (ii) an AI that is ECL-ish, and thereby pursues mutually-beneficial-trades with the rest of the multiverse.
One difference is that the latter will generate more gains-from-trade for other values. Similar to the question of “What values could make AI systems behave nicely towards other civilizations?”, the gain for other civilizations is out of scope for this post — see instead How ECL changes the value of interventions that broadly benefit distant civilizations .
But separately, it will also itself benefit from gains-from-trade. (Probably. It depends on some of the issues discussed in the appendix.) When we think about those potential gains (to the misaligned AI’s own values) we should value those according to the formula — at c as much as we would value benefits to our own values.4
How could we increase the likelihood that AI ends up reasoning well about decision-theory, by the lights of distant, ECL-ish AIs? The one thing we know for sure is that such AIs will themselves be ECL-ish, so probably they’d want other AIs with their values to have the preconditions for that — including EDT-ish (or maybe FDT-ish) decision-theories and probably some kind of updatelessness.
Just like above, interventions in this space also have plausible backfire risks. For one, AIs that act according to acausal decision theories seem harder to control from an alignment perspective. For example, they seem more likely to coordinate with each other in ways that humans can’t easily detect. For another, if AI starts thinking about acausal decision theories at an earlier time, it may be more likely that they make foolish decisions due to commitment races.
Other path-dependent abilities
Are there any other path-dependencies that would let us influence AIs’ long-run abilities, in a way that distant, ECL:ish AIs could approve of? I don’t know many great suggestions that don’t go into one of the above categories. But one candidate example (that’s admittedly highly related to both decision theory and values) could be to equip it with surrogate goals.
Appendix — Whose values get benefitted by ECL-ish AIs?
In Influencing values, I talk about how we benefit particular values a lot if we empower AIs with those values. But if those AIs are ECL-ish, they might just optimize for a compromise utility function anyway (as argued in the original paper on ECL, then called MSR) — without strongly weighting their own values. So are we really benefitting the AI’s own values, specifically?
Quick flag before I answer this: I’m very confused about the issues below, so it will be even harder than usual to understand what I’m writing about. The point of this section is less to communicate knowledge, and more to communicate a better sense of where I still feel plenty confused, and what sort of areas might need to be poked-at if we wanted to get a better sense of this stuff.
There’s a few different things to note.
Firstly, if everyone’s “compromise utility function” was identical, that would probably be because every ECL-ish actor correlated similarly much with every ECL-ish actor. (In particular, that there’s not any separate correlational clusters with different average values.) But if that’s the case, then the value of c should be 1. So in that case, there’s no disagreement with my formula. Thus, insofar as my methodology fails, it will be in cases that are more complex than “all ECL-ish actors optimize for a single compromise utility function”.
Secondly, in order to decide on a compromise utility function, distant actors may want to study what sort of actors both have power and are sympathetic to ECL. Such superintelligence-powered studies will probably be very accurate, and therefore take into account what decisions we make about what actors to empower.
Accordingly, if we empower some AI with some particular values, the overall effect would be for that AI to locally optimize for a compromise utility function and for the overall compromise utility function to shift in the direction of that AI’s values.
If this is the case, I expect that the overall effect would be similar to if the AI had simply been offered an opportunity to negotiate with different civilizations and strike a mutually beneficial bargain. In which case it makes sense to think separately about how (i) empowering that AI gives it access to extra resources, and (ii) ECL allows it to get some extra gains-from-trade.
While I think that’s a large part of the story (which makes me ok with leaning on this framework in this post), I recognize that it can’t be the whole story. In particular, the whole idea with this post is that we might be able to do ECL with these AIs. And we don’t fit the story above. We don’t have the ability to do detailed monitoring of what sort of actors are empowered, so we can’t be responsive to these kinds of power-shifts in the way that I just described. There are certainly some other actors like us, and there might be many more.
In our case, I think it’s plausible that even if we can’t do monitoring and balance power in the right way, the AIs we’re making deals with will be able to do this. This is an important part of the story for why I think it probably doesn’t matter a lot that we benefit values that are extremely common, as opposed to common-enough that they can afford to benefit us a commensurate amount. But here I feel like I’m stacking speculation on speculation, and don’t really know what I’m talking about.
And even if I take that seriously, there is, in fact, a remaining effect here. If you create ECL-ish representatives for a rare value-system, most of those systems’ resources might go towards compensating actors who empowered such values (in ignorance about whether there would be anyone to compensate them for that). In which case, creating those first few representatives would be more to the benefit of the compensated actors than the values held by those representatives. (Which is sort-of the reason for why the Influencing values-section concludes that it might be good to create ECL-ish, updateless AI systems.)
I repeat: I feel very out of my depth here.
How would they know what we want? These will be space-colonizing civilizations at technological maturity, so I imagine they could get a good idea by committing some tiny fraction of their resources to the study of what evolved species in our situation tend to want. (Including by running various kinds of simulations.)
Or for someone else to benefit us. I think about this deal framework as checking that there’s any win-win deal that involves us helping someone else, in which case it should be included in a grand bargain. But if we do our part in as many win-win deals as we can, that’s not just evidence that our imagined counterparts act in the same deals, but also evidence that other ECL-ish actors do their best to follow this procedure. And we could also get benefits from there.
This is for a few different reasons:
AIs with more modest values seem easier to study (less likely to actively try to mess up experiments).
AIs with more modest values seem more likely to agree to mutually-beneficial deals where they admit that they have misaligned goals, and we help them achieve those goals. (In exchange for the information that they are misaligned — and potentially in exchange for other services.)
AI with more modest values seem less likely to pursue world takeover if they escape their bounds.
It’s possible that the gains-from-trade that accrues to itself would be significantly larger than the value it generates for others. As an analogy: if a small country like Sweden lost the ability to trade with the outside world — I think that would be worse for Sweden than it would be for the rest of the world combined. (Specifically, I think this is true even if we’re talking about total harm, rather than per-capita harm. On a per-capita basis, it would obviously be much worse for Sweden.) My main intuition here is that the world economy benefits a lot from specialization and diversity in what products can be produced where — and the world economy would mostly have substitutes for Swedish goods, but Sweden would not have substitutes for the rest of the worlds’ goods.